Web scraping là quá trình sử dụng bots để trích xuất dữ liệu hữu ích từ các website dùng lưu trữ, phân tích hoặc trở thành nguồn cung cho các hệ thống khác. Nếu search trên các trang freelance sẽ thấy công việc này rất rất nhiều.

Vậy làm bot để scrapping một trang web có khó không ? Câu trả lời là khó và dễ, tùy thuộc hệ thống mà bot đến crapping có chức năng chống bot/scrap hay không. Và thường trờ một số trang cần trở thành member mới có thể scrapping được, hầu hết điều có thể lấy được data dễ dàng.
Ví dụ để scrapping một trang như là chợ tốt, mình chỉ cần tốn khoản 15 phút. Quá trình bao gồm :
1. Phân tích trang: công việc đàu tiên, và có thể xem là khó nhất không phải viết code, mà xe phân tích xem là sau lấy được data một cách thủ công. Lấy thủ công được rồi mới nghĩ đến viết bot. Khi đó mới biết có cần dùng cách gì đặc biệt không ? hay chỉ là lấy data thông thường.
Đầu tiên, chúng ta thấy chợ tốt có trang nhà (homepage) có chức năng hiện thị thông tin từ mới đến cũ.
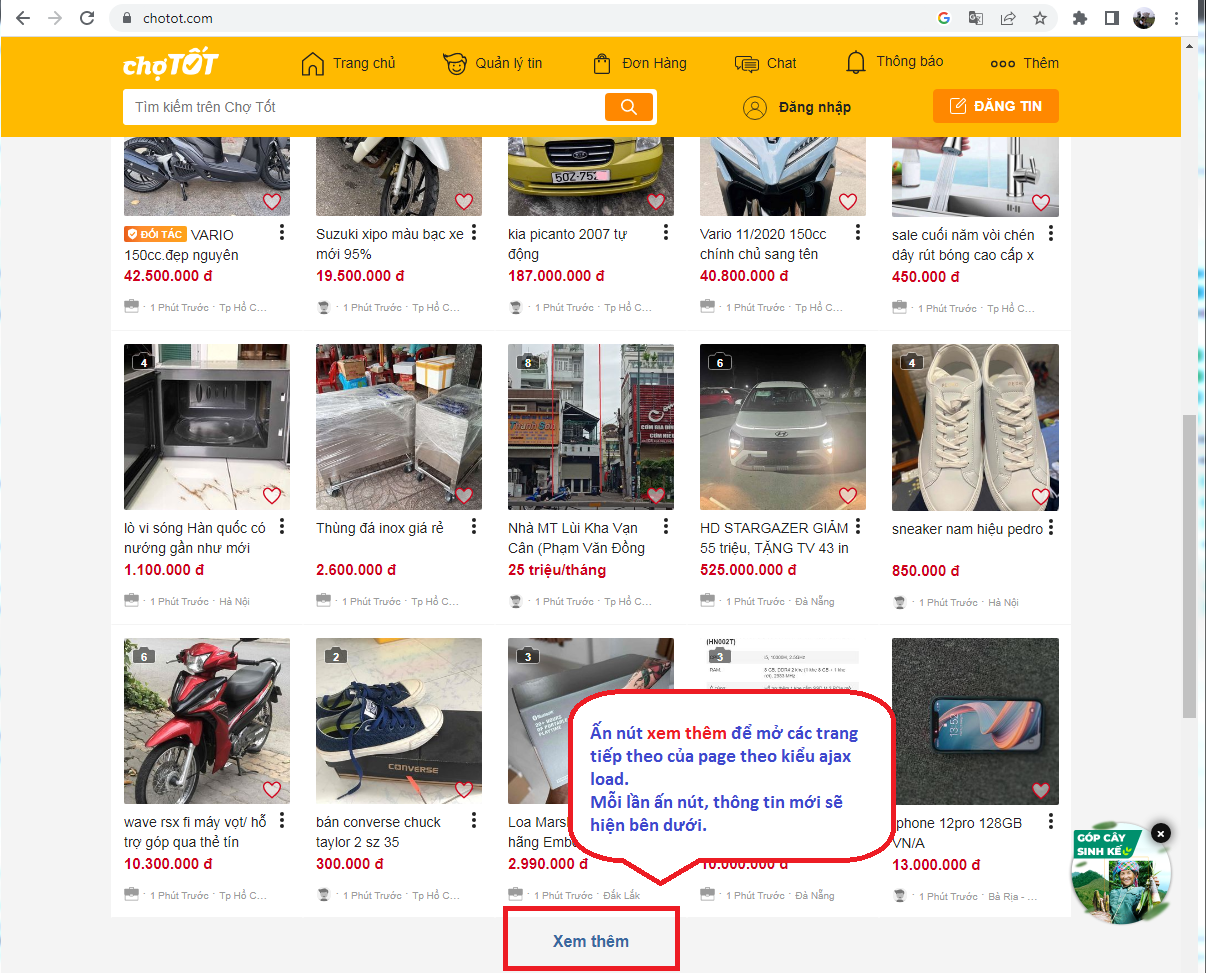
Phân tích các request load ajax sẽ thấy có url homepage có parameter là page và data trả về là 1 json chứa nội dung phần thông tin load ra được. URL này được gọi bằng phương thứ GET thông thường.
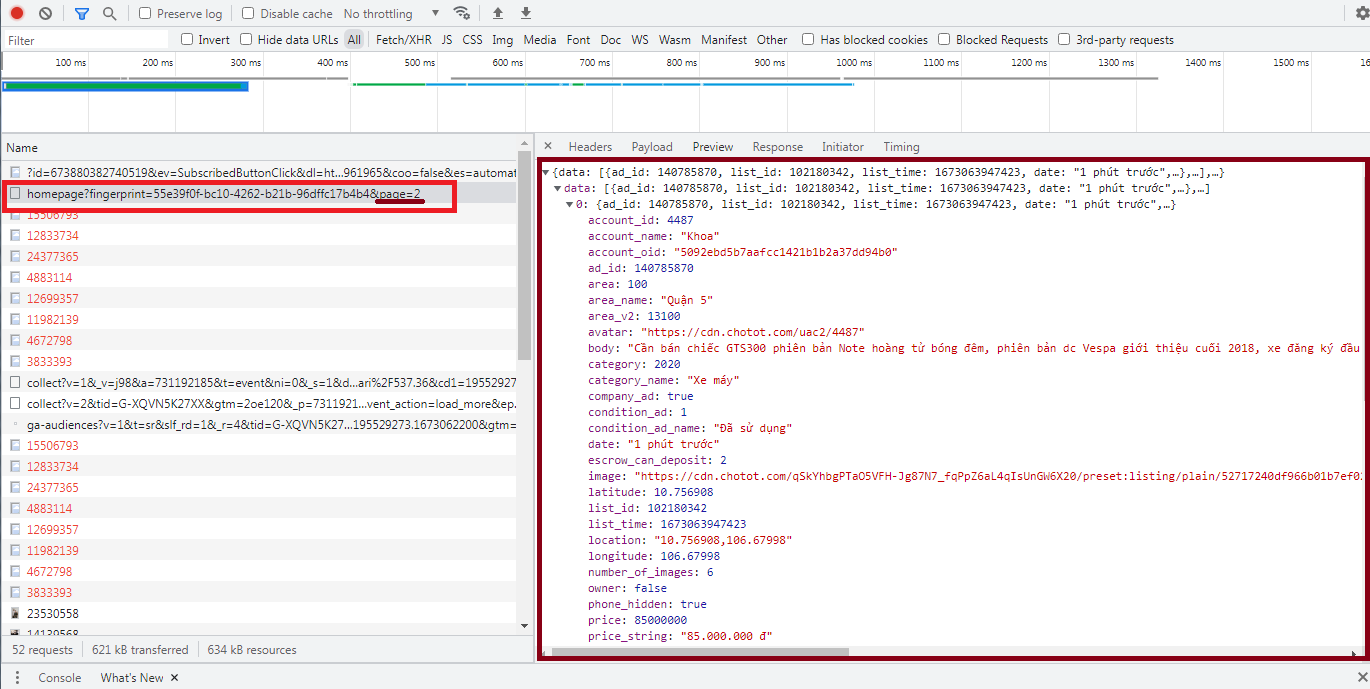
Vậy ta có thể kết luận hệ thống này có thể scraping bình thường, không cần thủ pháp gì đặc biệt khác.
2. Viết code:
Để viết scraping tool, bạn có thể dùng bất kỳ ngôn ngữ backend nào như Nodejs/PHP/Java/dotNet/Python, vì ngôn ngữ nào cũng hỗ trợ các module lấy request thông qua url, xử lý chuỗi (trường hợp data scraping là html) hoặc xử lý json (trường hợp data scraping là json). Trong ví dụ này mình dùng Nodejs vì đây là ngôn ngữ dễ học và ai cũng cần biết.
Nodejs hỗ trợ việc lấy request bằng package request và request-promise, JSON.parse để chuyển data text dạng json thành object Json.
Code để lấy 1 json data chợ tốt chỉ vài dòng như sau
var rp = require('request-promise');
main();
async function main() {
let rs = await run(1); //Lấy json data của trang 1
}
//Lấy json data của trang thứ [page], chuyển về dạng json
async function run(page) {
let rsHtml = await rp('https://gateway.chotot.com/v1/public/recommender/homepage?fingerprint=55e39f0f-bc10-4262-b21b-96dffc17b4b4&page=' + page);
let rs = JSON.parse(rsHtml);
console.log(rs);
}
Điểm khó nữa là lấy đến khi nào thì dừng, để trang hệ thống anti-bot thì nên làm thế nào. Mình thường dùng cách sau:
- Mỗi lần scraping 1 trang, sẽ cho dừng 2s.
- Khi nào lấy hết tin, thường khi craping mà không có data hoặc dấu hiệu nào đó cho biết đã hết . Như với chợ tốt, mối page trả về 20 mẫu tin, nếu thấp hơn 20 mẫu tin tức bạn đã duyệt hết tin của họ.
- Nên lấy tối đa N page (có thể 100 hoặc 1000 tùy như cầu) mà chưa hết thì dừng không cần lấy tiếp. Một phần các tin cũ quá không còn giá trị
Và đây là full code
var rp = require('request-promise');
var MAX_PAGE = 20; // Chỉ lấy tối đa 20 page
main();
async function main() {
let i = 1; //Biến đếm số trang, số trang bắt đầu là 1 (chứ không phải 0 như vòng lặp bình thường hay dùng)
let bool = true;
while(bool == true && i <= MAX_PAGE) {
bool = await run(i); //Lấy json data của trang 1
i++;
await sleep(1000); // cho dừng 1000ms
}
}
//Lấy json data của trang thứ [page], chuyển về dạng json
async function run(page) {
let rsHtml = await rp('https://gateway.chotot.com/v1/public/recommender/homepage?fingerprint=55e39f0f-bc10-4262-b21b-96dffc17b4b4&page=' + page);
let rs = JSON.parse(rsHtml);
console.log(rs);
if(rs.data.length < 20) return false;
return true;
}
async function sleep(ms) {
return new Promise(resolve => setTimeout(resolve, ms));
}
Phạm vi bài này mình chỉ hướng dẫn bạn lấy data về, còn về các xử lý khác như lưu trữ hay dùng thế nào là phần tiếp theo của bạn. Hy vọng các bạn có nhiều ý tưởng hay ho.
Bạn có thể lấy source từ github: https://github.com/circlequang/scraping-tool-tutorial/